

Performance Prediction in Action: Building Self-Healing API Systems
We've built a production-ready system that can foresee API performance issues. But what if it could not just predict problems, but automatically prevent them with a decision engine in the mix?


The Journey to Autonomous APIs
Remember our prediction system from the last article? It's doing a great job telling us when things might go wrong. But there's still a gap between prediction and action. In many organizations, the conversation goes something like this:
Alert: High latency predicted for checkout API in 15 minutes
DevOps: frantically provisions new instances
Alert: Cache hit rate dropping...
DevOps: adjusts cache settings
Alert: Database connections spiking...
DevOps: updates connection pool
Sound familiar? While our prediction system gives us a head start, we're still in reactive mode. Let's change that by building a system that can take intelligent, automated actions.
Architecture of a Self-Healing System
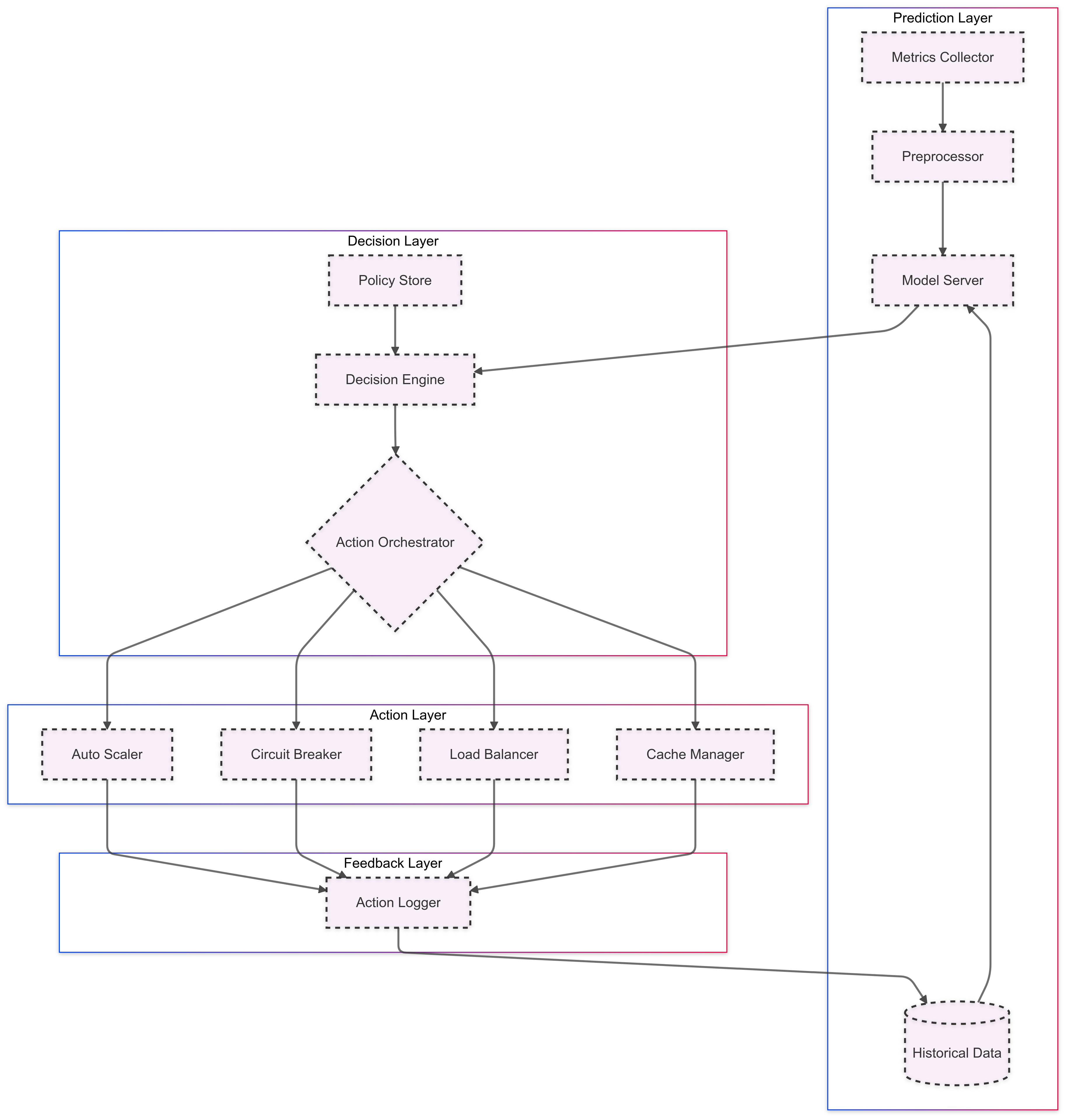
Our self-healing system builds on the existing prediction infrastructure, adding three crucial new layers:
Decision Layer: Evaluates predictions and determines appropriate actions
Action Layer: Executes mitigation strategies safely and reliably
Feedback Layer: Tracks action effectiveness and updates policies
Let's see how we can implement these new components while leveraging our existing codebase.
Building the Decision Engine
The Decision Engine is our first addition to the prediction system. It transforms predictions into actionable decisions based on configurable policies.
Have a look at its implementation in the source code.
Here's a more natural way to explain how our Decision Engine evaluates and acts:
The Decision Engine is like a skilled operator, constantly monitoring your API's vital signs through three key lenses. First, it evaluates risk by synthesizing multiple data points - how your API is responding to requests, whether errors are creeping up, and if your resources are under strain. Think of it as an early warning system that spots trouble before it impacts users.
Each API endpoint gets its own customized playbook - what we call policies. These aren't rigid rules, but rather smart guidelines that adapt to each endpoint's unique characteristics. For example, your checkout API might need stricter error thresholds but can tolerate slightly higher latency, while your product catalog API prioritizes consistent response times. These policies define everything from how aggressively to scale resources to when circuit breakers should kick in to prevent cascading failures.
When risks emerge, the engine doesn't just raise alarms - it takes action. Like a skilled pilot making constant adjustments, it might spin up new instances if load increases, tweak cache settings to improve hit rates, or adjust load balancing to optimize resource usage. Each action is calculated and proportional, ensuring stability while preventing over-reaction.
The art of automation isn't in eliminating human judgment, but in amplifying it.
Let's look at how we configure these policies:
endpoints:
/api/v1/checkout:
thresholds:
high_risk: 0.75 # Risk score that triggers immediate action
medium_risk: 0.5 # Risk score that enables preventive measures
scaling:
min_instances: 3
max_instances: 10
increment: 2 # Scale up by 2 instances at a time
threshold: 0.7 # CPU utilization threshold
circuit_breaker:
enabled: true
timeout: 30s
error_threshold: 0.05 # 5% error rate triggers circuit breaker
min_requests: 100 # Minimum requests before enabling
caching:
enabled: true
min_hit_rate: 0.8
ttl_increment: 300 # Increase TTL by 5 minutes if hit rate is low
load_balancing:
algorithm: round_robin
imbalance_threshold: 0.2 # Max allowed difference in server load
health_check_interval: 10s
/api/v1/cart:
thresholds:
high_risk: 0.8 # Higher tolerance for cart API
medium_risk: 0.6
scaling:
min_instances: 2
max_instances: 8
increment: 1 # More gradual scaling
threshold: 0.8
circuit_breaker:
enabled: true
timeout: 15s # Shorter timeout for cart operations
error_threshold: 0.02 # More sensitive to errors
min_requests: 50The policies are defined in YAML for easy maintenance and version control. Notice how we can tune different parameters for each endpoint based on its business importance and performance characteristics:
The checkout API has more aggressive scaling policies but higher risk tolerance
The cart API has stricter error thresholds but more gradual scaling
Each endpoint has customized circuit breaker and caching configurations
Now that we have our Decision Engine and policies in place, let's implement the Action Orchestrator that will safely execute these decisions...
Building the Action Orchestrator
The Action Orchestrator is the critical bridge between decisions and actions. It needs to handle action coordination, ensure safe execution order, and maintain system stability.
Code for the Action Orchestrator.
The Action Orchestrator is the conductor of our self-healing symphony, carefully coordinating each response to ensure harmony in our system. Like a well-rehearsed emergency response team, it follows a precise protocol when taking action.
Safety comes first. Before any action is taken, the orchestrator performs a thorough safety check - imagine a pilot's pre-flight checklist. It verifies there are no conflicting actions in play, ensures all parameters are within safe bounds, and confirms the system's stability won't be compromised. This methodical approach prevents the cure from being worse than the disease.
When it's time to act, the orchestrator moves with deliberate precision. Circuit breakers deploy first as the front line of defense, followed by scaling operations to adjust capacity. Finally, like fine-tuning an instrument, it makes more nuanced adjustments to caching and load balancing. Each action is carefully timed and monitored, with built-in limits to prevent overwhelming the system.
The circuit breaker implementation showcases this sophisticated approach in action. Rather than abruptly failing all requests when issues arise, it employs a gradual response - starting by diverting just 25% of traffic. This measured approach allows the system to test whether partial traffic reduction resolves the issue before taking more drastic action.
Recovery is equally thoughtful. Like a careful driver testing the road after a storm, the system first sends a small amount of traffic through the circuit breaker. If things look stable, traffic gradually increases. If problems persist, the system automatically extends its cautious period. Throughout this process, each endpoint maintains its own state, making decisions based on its unique circumstances and history.
The result is a self-healing system that combines the decisiveness of automation with the nuance of human judgment. Every action is tracked, measured, and analyzed, building a growing knowledge base that informs future decisions.
With our Decision Engine and Action Orchestrator in place, let's explore how the different action handlers work together to create a truly self-healing system
Implementing Action Handlers
At the heart of our self-healing system lies a sophisticated set of handlers, each playing a crucial role in maintaining API health. Think of it as an orchestra where each section contributes to the harmony of the whole system.
The auto-scaling handler is our forward scout, using historical patterns to anticipate and prepare for traffic changes. Rather than simply reacting to spikes, it's proactively spinning up new instances during known high-traffic periods. For our checkout API, this means seamlessly expanding capacity before Black Friday hits, not after the first wave of timeout errors. New instances are carefully warmed up and tested, like athletes stretching before entering a game, ensuring they're ready to handle production traffic.
"The best time to scale is before you need to."
Our cache management system works like a skilled inventory manager, constantly optimizing what's kept close at hand. During high-stakes events like flash sales, it adapts in real-time - keeping price data fresh with shorter TTLs while expanding cache space for product details that shoppers will repeatedly request. It's particularly clever about pre-warming caches for items featured in promotions, ensuring the first wave of enthusiastic shoppers gets the same snappy response as those who come later.
The load balancer acts as our traffic conductor, orchestrating requests with a sophistication that goes beyond simple round-robin distribution. It understands that not all endpoints are created equal - some are more sensitive to latency, others to database load. When an endpoint starts showing signs of stress, the load balancer doesn't just abruptly redirect traffic. Instead, it orchestrates a graceful migration, taking into account everything from geographic proximity to database connection limits.
Standing guard behind all of this are our circuit breakers - the ultimate safety net. But unlike traditional circuit breakers that simply cut off traffic, ours act more like smart limiters. They gradually reduce load when they detect issues, carefully test the waters during recovery, and maintain separate policies for different endpoints. It's like having a skilled operator watching each service, ready to step in with just the right amount of intervention when needed.
Feedback Loop: Learning from Every Action
The true power of our self-healing system lies not just in its ability to take action, but in its sophisticated learning capabilities. Like a skilled engineer, it maintains a detailed logbook of every intervention, carefully analyzing what works and what doesn't. This isn't just simple pass/fail tracking - it's a comprehensive analysis framework that helps the system get smarter over time.
Every time an action is taken, whether it's scaling up instances or adjusting cache settings, the system calculates precise improvement metrics. For scaling actions, it looks at latency improvements. A 30% reduction in response time is logged as a clear success, while a marginal 2% improvement might suggest the need for different strategies. For circuit breakers, the focus shifts to error rate reductions, tracking how effectively they prevent cascading failures.
But the system doesn't just track individual metrics - it looks for patterns and correlations. Using a 24-hour sliding window of historical data, it builds a rich understanding of what works best for each endpoint. For instance, it might discover that the checkout API responds better to cache adjustments during peak hours, while scaling actions are more effective for handling flash sales.
The learning process is particularly sophisticated when it comes to handling side effects. Every action's ripple effects are carefully documented. If scaling up an instance improves latency but causes unexpected spikes in database load, this gets factored into future decisions. The system maintains a frequency map of these side effects, helping it anticipate and mitigate potential issues before they occur.
What makes this feedback loop particularly powerful is its ability to adapt over time. Through continuous trend analysis, it can detect when strategies that worked well in the past start becoming less effective. Success rates, improvement percentages, and action durations are all tracked using rolling averages, allowing the system to smoothly adapt to changing conditions.
Consider how this plays out in practice: When the system notices that scaling actions for a particular endpoint have a success rate dropping below 70%, it automatically begins favoring alternative strategies. If cache adjustments consistently show better improvements (tracked down to percentage points), the system gradually shifts its approach. This isn't just reactive learning - the system uses these insights to proactively adjust its thresholds and fine-tune its decision-making parameters.
The results of this learning are immediately visible in the system's decision-making. Each endpoint develops its own profile of effective strategies, timing considerations, and risk thresholds. What starts as a general-purpose healing system evolves into a highly specialized guardian, intimately familiar with the quirks and requirements of each part of your API infrastructure.
Beyond the Code: The Journey Forward
As we reach the end of our exploration into self-healing systems, remember that this is more than just code - it's a fundamental shift in how we think about system reliability. Start small, perhaps with a single non-critical endpoint. Let your system learn and evolve gradually. While automation is powerful, keep human expertise in the loop. Think of it as augmenting your team's capabilities rather than replacing them.
Remember: A truly resilient system isn't one that never fails, but one that gracefully recovers and learns from each incident.
Ready to begin your journey toward automated healing? Check out our implementation on GitHub and join our growing community of practitioners building more resilient systems.